
Data Manager: creating an ETL pipeline like no other

In this month’s tech blog, we speak to Adam, Nik and Niall about one of the latest projects the Tenzo developers have been working on: our new ‘Data Manager’. As an analytics company, Tenzo obviously has to have the framework in place to be able to manipulate data from many different sources and present it in a unified way for customers. The main goals for this new Data Manager was to ingest data sources kept in silos into centralised data warehouses to allow for new kinds of insights and homogenise datasets to fight “dirty” data and allow for replicable analytics.
In this open and frank conversation, Adam, Nik and Niall discuss some of the shortfalls of our previous system which led to the creation of Data Manager, as well as the challenges along the way. They also explain how this new tech will be able to support Tenzo’s continued exponential growth, a new and improved ETL pipeline, and what they’re most excited about. Enjoy!

Before we begin, could you briefly introduce yourselves?
Adam Taylor (AT): I’m Adam, one of the co-founders of Tenzo and I lead all things tech and product at Tenzo.
Niall French (NF): I’m Niall and I’m a Senior Full-Stack Developer at Tenzo.
Nik Davis (ND): I’m Nik and I’m a Full-Stack Developer at Tenzo.
Great, thanks for agreeing to this interview! Let’s start at the beginning, why did you start thinking of the idea of Data Manager and why is it so important for the restaurant industry?
AT: Increasingly, we’re seeing that customers want more and more data sources in Tenzo, particularly as more data sources are now on the cloud and as the restaurant tech stack becomes more fragmented. So as demand increases for more data sources in Tenzo, we want to enable access to them and to do it in a fast and consistent way.
“As demand increases for more data sources in Tenzo, we want to enable access to them and to do it in a fast and consistent way.”
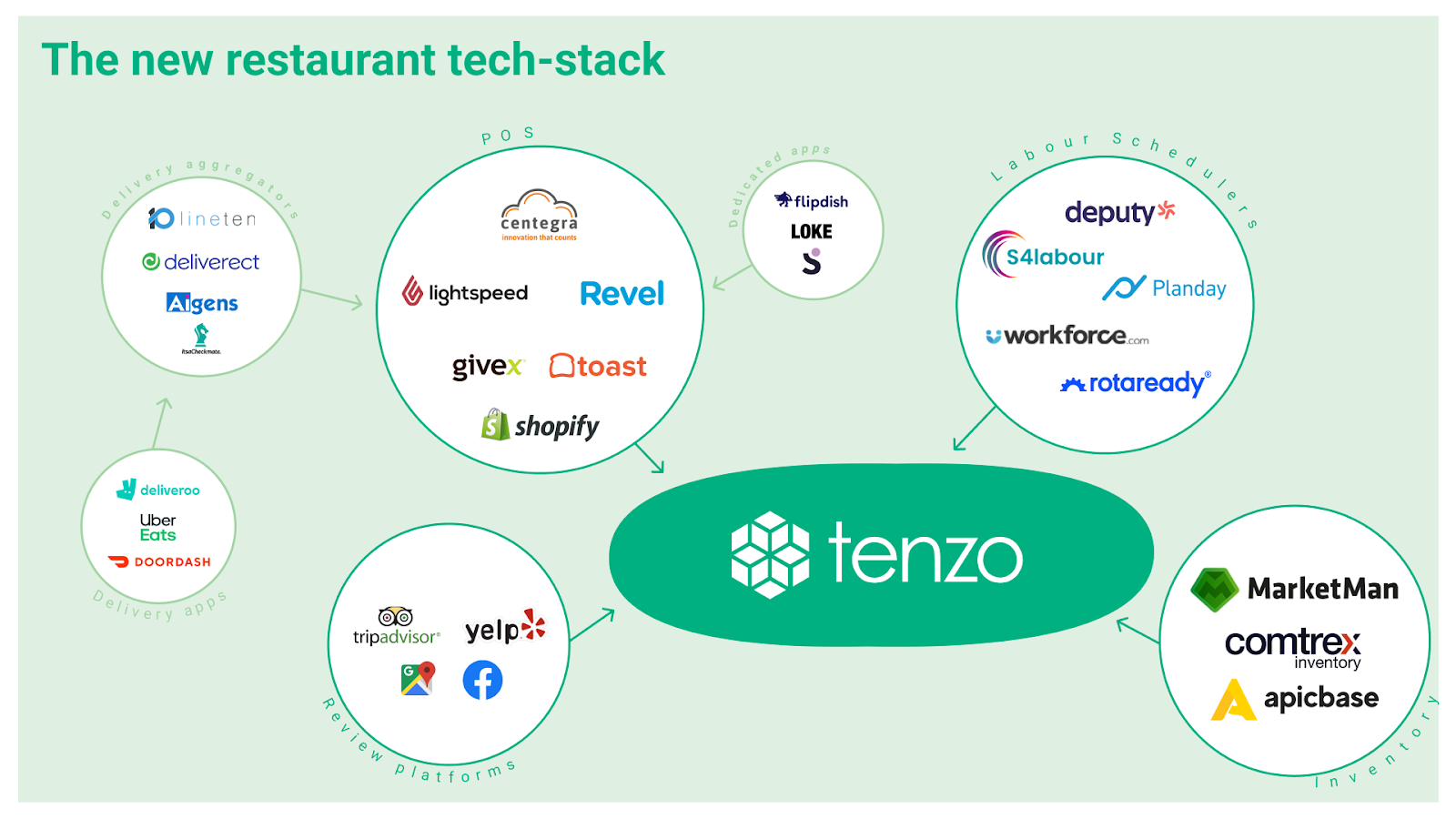 The new restaurant tech-stack
The new restaurant tech-stack
So, as that process of integrating more data sources involves a lot of manipulation of data – whether it’s reimporting data, setting up customers, or even self sign-up – we wanted it to be as consistent as possible from the minute you set up data all the way to getting that data through to the customer as insights. So a big piece of this whole project was around consistency and ease of use. Niall, Nik, I don’t know if you want to add anything…
ND: I guess you could add that internally, we were juggling all these different tasks and we wanted to standardise them and make our development process easier. We also found that half the time spent debugging was figuring out which specific task had gone wrong to produce a problem so cutting down that time helps us just develop faster.
NF: I would say that most of our imports were actually using the same tasks before data manager as part of the first set of ETL changes, but the way I look at it, one of the things Data Manager gives us is greater resiliency because we’ve changed the way we structure the process. Data now comes in in blocks and those blocks can’t interfere with each other anymore. To me, that’s one of the main benefits: resilience and reliability.
So when you were coming up with the idea for Data Manager, did you think it would be more of a customer-facing product or more of an internal product?
AT: The initial idea started from internal pain. We were realising that we had two problems really:
1) the Customer Success team was finding it very hard to work. Any time they wanted to set up a customer, any time they wanted to reimport a day’s worth of data, they were having to go to dev and say, ‘hey, can you run this script?’.
2) And then, on the engineering side, we were getting to the point where we were saying, ‘ok, we need to debug this issue, give us a couple of days to go fix this problem.’
So, the idea of Data Manager really originated in the pain we were feeling and the fact that the previous system wasn’t really scalable. Frankly, we could not have on-boarded the level of customers that we’re onboarding today with our old technology. We would have just fallen over.
 A new way to add APIs
A new way to add APIs
So in a way, necessity was the real motivator. We absolutely had to solve this problem. And, by the way, everybody generally used to hate working on integrations. It was viewed as a boring thing to do because a lot of it was quite painful and you would spend a lot of time sitting around waiting for things and not really using your brain. Now we’ve gotten rid of that.
We’ve also now built a tool for Customer Success (CS) that made it really easy for CS to set up data sources and set up new customers faster than ever before. That also benefits customers. We currently have customers that are setting up Facebook and Google themselves, but, with this new tool, they could connect lots more data sources themselves and I think they will be soon.
“We’ve also now built a tool for Customer Success that made it really easy for them to set up data sources and set up new customers faster than ever before.”
We also have data coming in even faster than before. In fact, we have one customer where we’re loading their POS data every ten minutes, which is a bit of a stars-aligning moment in that we really couldn’t have done that in a pre-Data Manager world or pre-data block world.
It sounds like Data Manager has really made your processes a lot simpler! But while the effects sound great, what really is Data Manager? What’s going on in the background to make this fantastic tool?
NF: There’s a whole bunch of engineering that goes along with it, but fundamentally, we’ve changed how we think about data coming into Tenzo. We’ve changed our view of what a unit of data that comes into Tenzo is.
Previously, we hadn’t formalised it in a structural sense, we just had a bunch of tasks and they went and fetched a bunch of stuff and they loaded a bunch of stuff, but there wasn’t much structure to it.
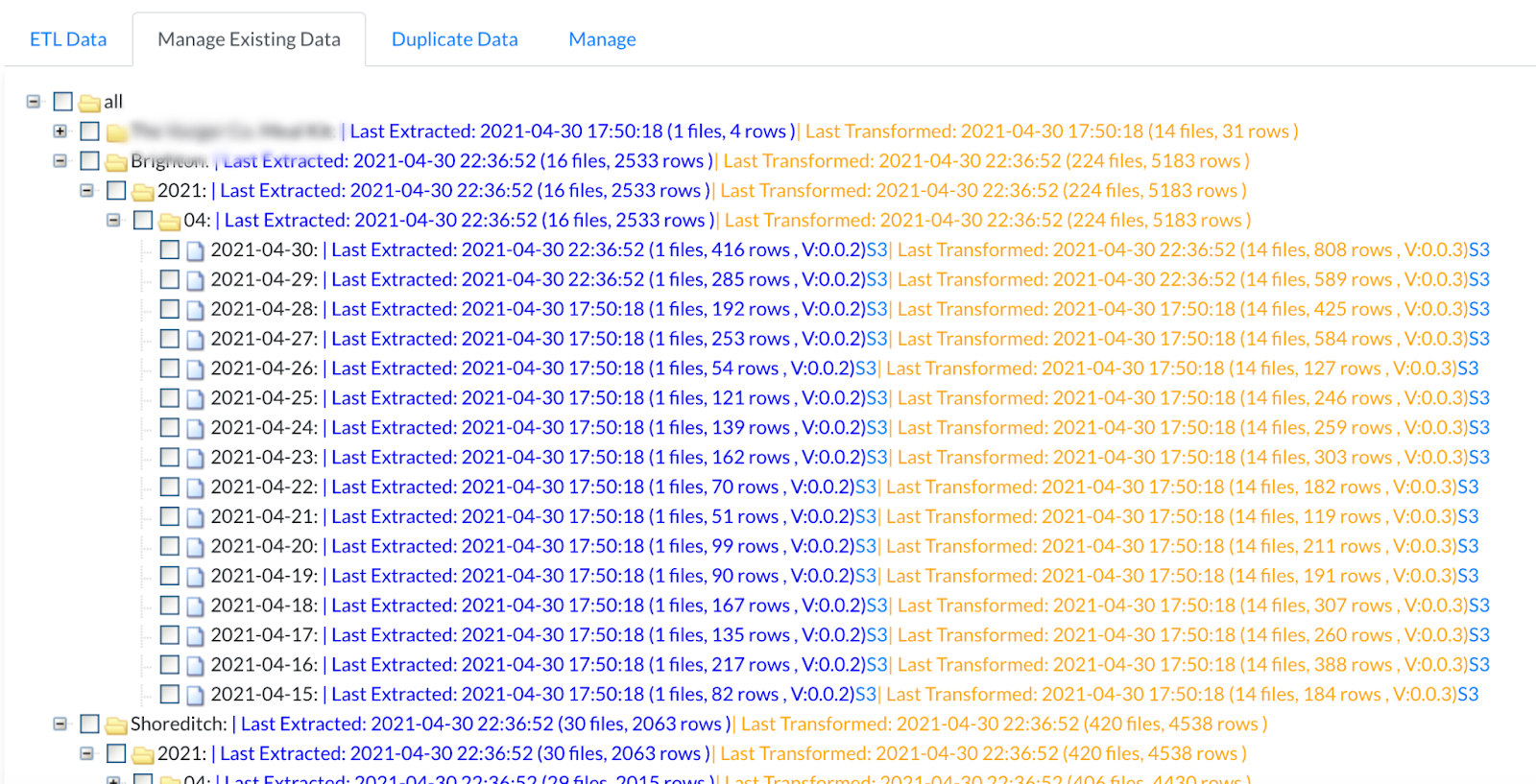 ETL data dashboard
ETL data dashboard
AT: Part of it is just the language we use to talk about the data as well as having a framework. The framework stems from pull and push APIs and then we’ve got streams, which are pretty much flows of data. Then within the stream you’ve got the block and actually this block/stream, push/pull idea is an organising framework and a way for us to then talk about it. That’s provided quite a lot of clarity.
NF: In terms of the tech side of things, moving all of our tasks to Airflow was pretty fundamental as well.
ND: Yeah, and building on what Adam said about this giving us a new way to talk about data, it’s also actually changed how we use and move data around – that’s fundamental with blocks.
Data Manager has not only given us a way to talk about data and how it moves, but has also given us the tool to literally move it around. This has been especially helpful when working locally. We can now really easily reproduce errors just by getting the exact same bits of data that caused an issue, because we know it was from a certain block. We can then rerun it. Blocks have enabled us to use the exact same data to interrogate any issues. And yes, Airflow.
So does Airflow sit within Data Manager then?
NF: Airflow is a framework in which we run tasks and any of the background tasks that run for Data Manager run on Airflow, but not all of Data Manager is running Airflow. There are other parts to that system.
What kind of parts are there?
NF: There’s an API part, there’s a part in the Tenzo platform, there are new features that we use on a new frontend that allow us to select data to reimport and query all the different blocks that have been imported.
AT: I would describe Data Manager as the product and Airflow is one of the tools by which we deliver that, but we also use lots of AWS tools as well for the actual infrastructure. Data manager is built on S3 which is just their file storage and we’re running ECS, we’re now using Terraform, so infrastructure-as-code…
NF: Fargate and EFS – those are great. Those are two things that we use now that we weren’t using previously. And having an EFS drive that’s shared between all our workers allows us to see if everything is working.
In our old ETL tasks, 90% of the time was spent uploading and downloading files from S3. Now we’ve managed to remove that as a blocker, so it still happens but it just doesn’t block data from loading, it doesn’t have to happen simultaneously – it can happen in parallel or off in a side process. Restructuring how all those tasks work has removed a lot of the time-suck from that process, so we can get data straight into Tenzo.
“Restructuring how all our tasks work has removed a lot of the time-suck from the process, so we can get data straight into Tenzo.”
That’s pretty epic, but you must have run into some challenges along the way? If someone else were to try and do this sort of thing, what advice would you give?
ND: (laughs) where to start?
NF: Nik getting Airflow configured correctly, that was a big project that you spent a lot of time working on…
ND: Yeah, there was a lot of configuration to be done to get things working exactly as we wanted. Making sure that EFS was working was key so that all these different systems and workers could use this file system to talk to each other. We needed to configure it, set it up and provision it within AWS and then deploy it.
All of that required a lot of iteration from the point of being able to run Airflow locally and see that our code worked through to actually extracting data and doing something with it. Going from that to actually having a production and deployment that’s stable enough and secure enough, but that we were also able to benefit from the web server where we can actually look and inspect everything was the challenge.
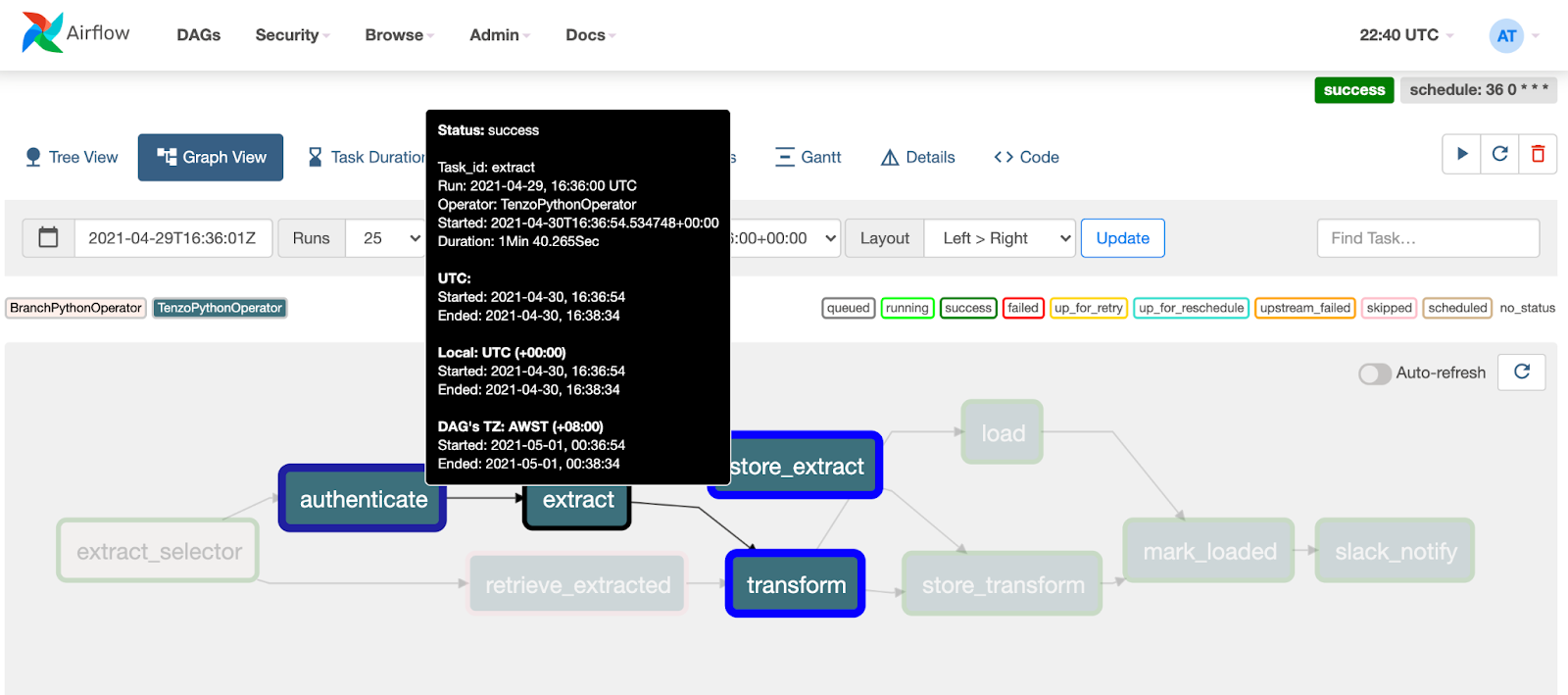 An example of one DAG in Airflow
An example of one DAG in Airflow
NF: There was a bunch of stuff that Nik did to help us to run things locally and pull blocks and he created a bunch of scripts that were super useful. For example, now if something crashes we get an error email that has all of the information in it that we can copy and paste, add some credentials and reproduce it locally in the space of 30 seconds. Previously, we wouldn’t have been able to do that because we would have had to run the extract part locally and we wouldn’t have had the exact same data, or data might have changed since we queried it.
AT: It’s life changing by the way… When you think of some of the pain from before…
“It’s life changing by the way.”
NF: It means we can reproduce issues in 30 seconds that previously might have taken us an hour of running code and re-extracting data to find what was broken.
ND: From a dev point of view, that’s been the single best thing to come out of the process for us. There are a lot of ‘best things’ that have come out, though – if you ask CS they’d have a different answer, whether that’s reimporting or set up, I don’t know. But for us, this is the best just because it’s a huge time saviour.
Every time there’s an ETL error, the thought process used to be ‘oh no, who’s going to look at this one?’ whereas now it’s ‘yep, I can look at that’ and in 5 minutes we might even have a fix, and that’s game-changing. These issues happen, obviously they’re going to happen, but they don’t slow us down now. It means if you’re working on something, you can do a quick couple of integration fixes and then you’re back to it immediately. Whereas before, you’d have to schedule a whole day for these things.
AT: As a side note, it does show the value for the dev team to spend time to reduce time to do everything else. It’s little things like Django set up, for example. When you run a script it used to take 20 seconds to start Django when you run locally and now we’ve cut that out. So that’s 20 seconds saved every time and that really does start to add up and reduces pain.
One of the challenges that we overcame that we haven’t mentioned yet was technical debt. We had 40 different integrations that were all in the old model. And every time we do something new, we have to figure out a way to migrate all the technology across. Migrating stuff from old to new is hard because you’ve already got a lot of moving parts that you cannot break and you’ve already got live customers that are working in one way and Data Manager makes this far easier.
NF: I think one of the main benefits, in terms of dev, is just unifying everything under Data Manager so everything works the same way. It gives the team a common understanding of what the different parts of an integration are.
Every data source that we have in Tenzo has an extractor and that extractor is responsible for going and getting that data, saving it in the right format, in the right place, and then telling us what it found or getting the data that we asked for in the first place. Then, all of that data that’s been extracted goes through another common set of code. What this means is that if you understand how it works for one integration, then you can understand how it works for all of the integrations. Previously, it might have been much more difficult for someone who hadn’t worked on an integration to go and debug that integration, but now they can so it makes the dev team much more flexible.
 Datasource setup form
Datasource setup form
AT: I think, and this is a bit jargony, but now rather than having horizontalisation of tasks, we’ve now verticalised them. Previously, we thought about a Lightspeed integration or a Rotaready integration or a Revel integration. Now, we think about extract, or transform or even the sub-operations within transform, or even saving the data, so we’re not optimising the horizontal integration anymore but instead the verticals at each stage for every integration. Everything we now optimise is entirely reusable across everything else; if you make a step better, you’ve made it better for every single integration in Tenzo.
NF: If you have a problem with one step that affects a bunch of different integrations, you now fix it once and you fix it for all of them. It’s much much more maintainable.
“If you have a problem with one step that affects a bunch of different integrations, you now fix it once and you fix it for all of them.”
The fact that you are able to access so many different data sources in this simple way, does that give customers more flexibility in their data sources?
AT: The short answer is yes, but maybe we’ll just elaborate a bit more there. It allows us to get more data sources in faster. A big part of what it enables is for us to unify schemas. A big part of what makes our integrations so complicated is that we’re trying to take 30 different POS’s that have 30 different schemas and translate that into one single schema. So if you were using Power BI or if you were building your own platform, you wouldn’t be doing that step. You’d just extract the data and then load it straight into a database in the format that it came from the original schema and you’d build a dashboard on it.
So then the question is, is it worth this schema unification step as that’s what adds all the complexity. What is the benefit of it to customers? By unifying schemas:
1) you get our library of cards. You get all of the insights and learnings that we already know work for customers. We know what things people want to see. So schema unification gives you the benefit of now being able to leverage the collective brain on cards and insights to discover.
2) the second would be forecasts. When you’re using the same schema, we can use our forecasting tech on top of it which has already been tested on lots of other people to predict your sales.
So it’s this unified schema which enables the amazing insights we’re able to provide.
That all sounds amazing, so where do we go from now, what’s next?
AT: I’m so excited! So much! The beauty is now that everything is consistent across each step, we can now start looking at the individual steps and start asking how we really optimise them.
The two or three topics to call out are:
1) Testing – we want to test every eventuality so we know it’s as stable as possible.
2) And then looking at individual steps. For example, transforms: I think there’s many opportunities to make creating and debugging transforms easier.
3) There’s also a lot on general throughput and latency so we can get data in faster from beginning to end.
But transform tooling, overall pipeline speed and throughput and then accuracy is where we’re going.
NF: One of the other things that it enables is customers to do self set up. So soon customers will be able to visit a set up part of Webapp and add a whole new datasource by themselves without having to call Customer Success.
It also allows us to add custom data sources, so now we can add whatever data you have from your own restaurant that might be different from everyone else’s. We can load these custom data sources into Tenzo and join that to your existing reporting
Does that now mean that customers will be able to see as many data sources as they want to (within reason)? Say I have 4 POS and a delivery platform, can I see it all side by side?
NF: If you have the data, you can get it into Tenzo.
“If you have the data, you can get it into Tenzo.”
AT: We have 40 integrations at the moment, I’d like to go up to 400. And do I now feel like we have the frame to be able to do that? Yes.
ND: There’s also just the general scaling idea. By using Airflow the way we’ve set it up and the way we run the tasks, we’re really well positioned to scale. The bottlenecks are gone; we can scale up as much as we want.
Also, up until now we’ve been doing all these things to get it running and get it running reliably, but now that we’ve succeeded there’s a lot more cool things we can do with Airflow. There’s metrics we can get out of the way we’re processing data, and there’s a whole bunch of other features that we can put in and use.
AT: Yeah, the scalability point is another big one I’m excited about. I’m not scared to scale to huge numbers of clients. Technically, can we serve 1,000,000 restaurants? Yes, we’ve got the frame.
Thanks so much for breaking this down guys!


